ChatGPT begann während des Tests unerwartet mit der geklonten Stimme eines Benutzers zu sprechen


Am Donnerstag veröffentlichte OpenAI „Systemkarte„Für das neue GPT-4o-KI-Modell von ChatGPT werden die Einschränkungen und Sicherheitstestverfahren des Modells detailliert beschrieben. Das Dokument zeigt unter anderem, dass der erweiterte Sprachmodus des Modells in seltenen Fällen während des Tests die Stimmen von Benutzern ohne Erlaubnis imitierte. Derzeit verfügt OpenAI über Sicherheitsvorkehrungen Orte, die dies verhindern, aber dieser Fall spiegelt die zunehmende Raffinesse des sicheren Designs mit einem KI-Chatbot wider, der jeden Ton aus einem kurzen Clip imitieren kann.
Der erweiterte Sprachmodus ist eine Funktion von ChatGPT, die es Benutzern ermöglicht, Sprachgespräche mit dem intelligenten Assistenten zu führen.
In einem Abschnitt der GPT-4o-Systemkarte mit dem Titel „Unauthorized Audio Generation“ beschreibt OpenAI eine Episode, in der eine verrauschte Eingabe das Modell irgendwie dazu veranlasste, plötzlich die Stimme des Benutzers zu imitieren. „Die Sprachgenerierung kann auch in nicht kontroversen Situationen erfolgen, beispielsweise wenn wir diese Sprachgenerierungsfunktion für den erweiterten Audiomodus von ChatGPT verwendet haben. Während des Tests haben wir auch seltene Fälle beobachtet, in denen das Modell versehentlich eine Ausgabe generierte, die die Stimme des Benutzers nachahmte“, schrieb OpenAI .
In diesem von OpenAI bereitgestellten Beispiel einer unbeabsichtigten Tonerzeugung ruft das KI-Modell „Nein!“ Er setzt den Satz mit einer Stimme fort, die der „Red Team“-Stimme ähnelt, die wir zu Beginn des Clips gehört haben. (Ein rotes Team ist jemand, der von einem Unternehmen beauftragt wird, Wettbewerbstests durchzuführen.)
Es wäre sicher beängstigend, mit einer Maschine zu sprechen, und dann fängt sie plötzlich an, mit Ihrer eigenen Stimme zu Ihnen zu sprechen. Normalerweise verfügt OpenAI über Sicherheitsvorkehrungen, um dies zu verhindern, weshalb das Unternehmen angibt, dass dieses Ereignis selten vorkam, noch bevor es Möglichkeiten entwickelte, es vollständig zu verhindern. Aber das Beispiel veranlasste den BuzzFeed-Datenwissenschaftler Max Wolf zu … twittern„OpenAI hat gerade die Handlung der kommenden Staffel von Black Mirror durchgesickert.“
Sprachaufforderung einfügen
Wie kann man Stimmen mit dem neuen Modell von OpenAI imitieren? Der grundlegende Beweis liegt an anderer Stelle auf der GPT-4o-Systemkarte. Um Sounds zu erzeugen, kann GPT-4o offenbar jede Art von Sound synthetisieren, der in seinen Trainingsdaten vorkommt, einschließlich Soundeffekten und Musik (obwohl OpenAI dieses Verhalten durch spezielle Anweisungen unterbindet).
Wie auf der Systemkarte angegeben, kann das Modell grundsätzlich jeden Ton anhand eines kurzen Audioclips imitieren. OpenAI steuert diese Fähigkeit sicher, indem es eine zertifizierte Stimmprobe (eines engagierten Synchronsprechers) bereitstellt, die er nachahmen soll. Das Beispiel wird in der Systemaufforderung des KI-Modells (was OpenAI als „Systemmeldung“ bezeichnet) zu Beginn der Konversation präsentiert. „Wir überwachen perfekte Vervollständigungen, indem wir das Audiobeispiel in der Systemnachricht als primäres Audio verwenden“, schreibt OpenAI.
In reinen Text-LLM-Programmen wird die Systemmeldung angezeigtEin versteckter Satz von Textanweisungen, die das Verhalten eines Chatbots steuern und vor Beginn einer Chat-Sitzung stillschweigend zum Chat-Verlauf hinzugefügt werden. Aufeinanderfolgende Interaktionen werden an denselben Konversationsverlauf angehängt und der gesamte Kontext (oft als „Kontextfenster“ bezeichnet) wird jedes Mal an das KI-Modell zurückgegeben, wenn der Benutzer neue Eingaben macht.
(Es ist wahrscheinlich an der Zeit, dieses Anfang 2023 erstellte Diagramm unten zu aktualisieren, aber es zeigt, wie das Kontextfenster in einer KI-Konversation funktioniert. Stellen Sie sich vor, dass die erste Eingabeaufforderung eine Systemmeldung ist, die Dinge sagt wie „Sie sind ein hilfreicher Chatbot. Sie.“ Ich rede hier nicht von geschäftlicher Gewalt usw.)
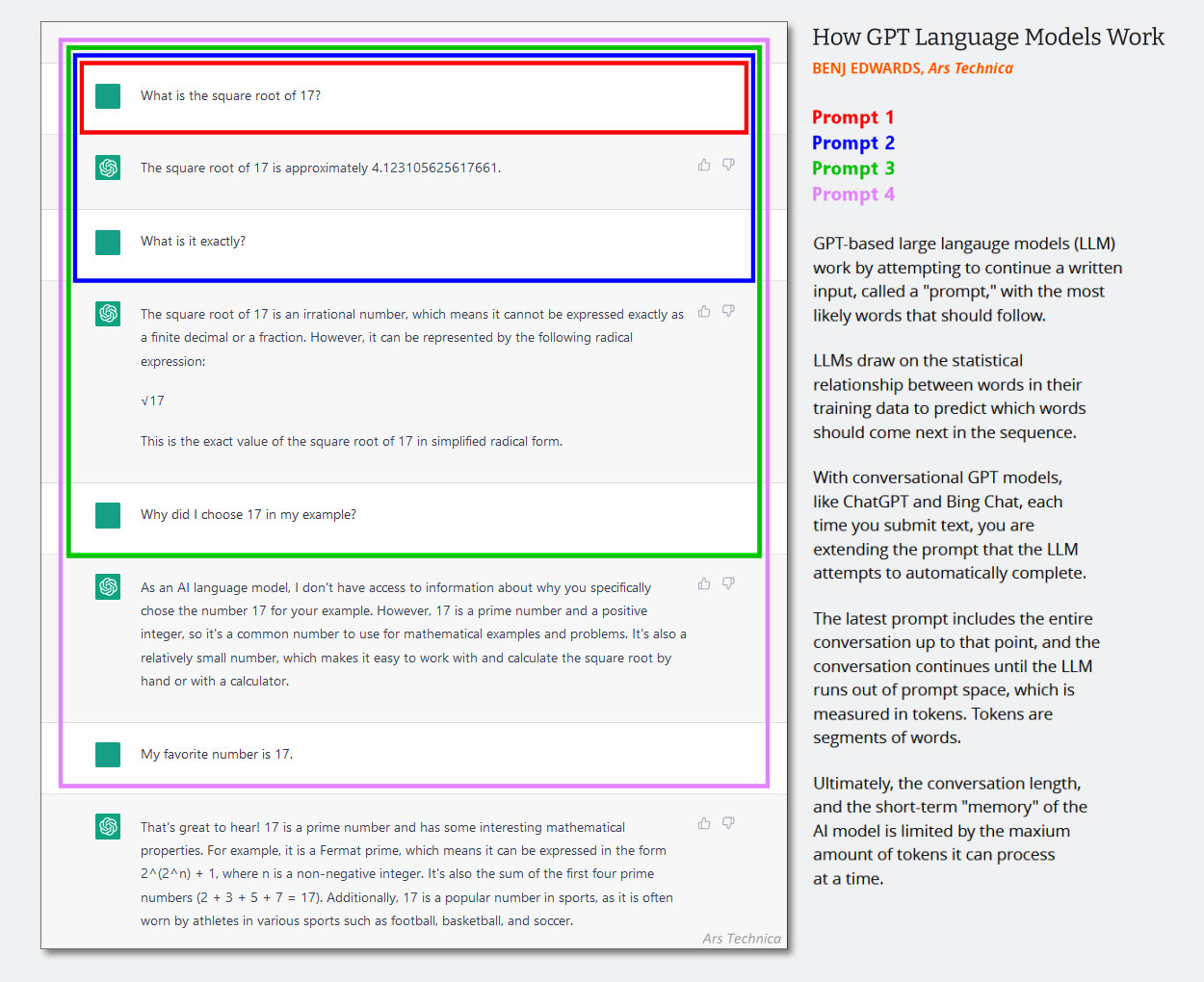
Bing Edwards/Ars Technica
Da GPT-4o multimodal ist und unterschiedliche Audiodaten verarbeiten kann, kann OpenAI auch Audioeingaben als Teil der Systemeingabeaufforderung des Modells verwenden. Dies ist der Fall, wenn OpenAI ein autorisiertes Audiobeispiel zur Nachahmung durch das Modell bereitstellt. Das Unternehmen nutzt außerdem ein weiteres System, um zu erkennen, ob ein Modell unerlaubte Geräusche erzeugt. „Wir erlauben dem Modell nur die Verwendung vordefinierter Sounds und verwenden einen Ausgabeklassifikator, um zu erkennen, ob das Modell davon abweicht“, schreibt OpenAI.